Bloom Filters - A Smarter Way to Check If "We've Seen This Before"
When you build systems like signups or search engines, one common question keeps popping up:
"Have we seen this before?"
This is key for:
- Checking if an email or username is already registered
- Avoiding duplicate URLs in a crawler
- Speeding up cache checks
Let’s start by looking at how we’d solve this problem traditionally — and why that doesn’t scale.

The Conventional Approach
When you want to check if an email, username, or URL already exists, the first approach is often a hash table.
Example
- Store each item in a HashSet or Map
- On insert or lookup, hash the item and check if it's present
This works fine at a small scale. But as data grows into millions or billions, challenges appear.
Common Strategies
Hash Tables:
- Fast lookup (
O(1)) - Problem: High memory usage; every key must be stored fully
Sharding:
- Distribute data across multiple servers
- Problem: Introduces network latency and coordination overhead
Caching:
- Use Redis or Memcached for hot keys
- Problem:Limited memory; cache evictions make lookups unreliable
Core Issue
All these methods store full keys, making them memory and latency-expensive at scale.
Why Use Bloom Filters?
A Bloom Filter is a space-efficient, probabilistic data structure that answers:
This item is definitely not in the set
OR
It might be in the set
The keyword here is: “might”.
Simple Analogy: The Stamp Card
Imagine a bakery giving stamp cards.
A customer visits → you stamp spots based on their name
They return → you check if those stamps exist
If none match → they’re definitely new
If some match → they might have visited before
That’s how Bloom Filters behave.
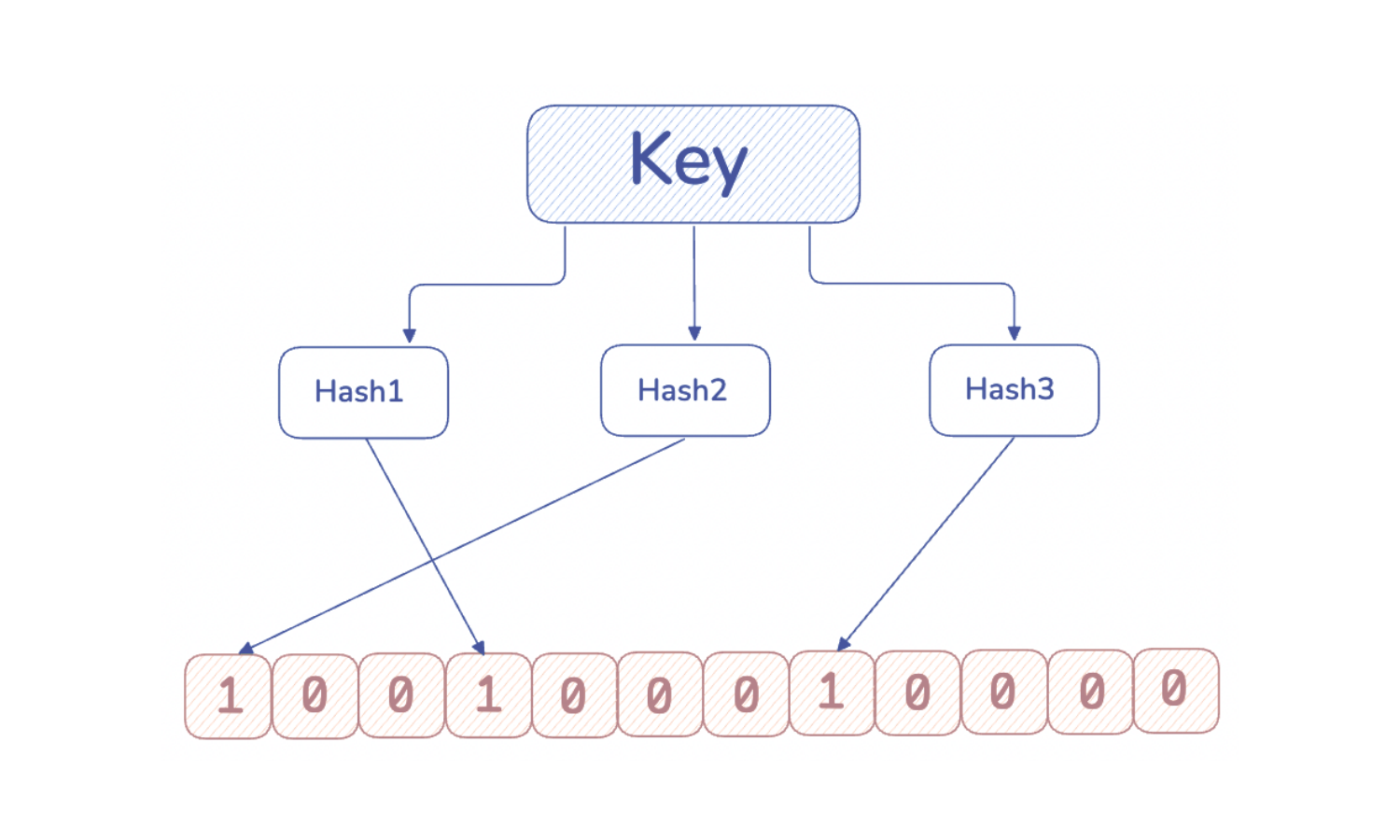
How Bloom Filters Work
A Bloom Filter consists of:
- A bit array of size
m, initialized to 0 kindependent hash functions
To add an item
- Hash the item with
kfunctions - Get
kpositions in the bit array - Set all those bits to
1
To check an item
- Hash again with the same
kfunctions - If any bit is 0 → item is definitely not in the set
- If all bits are 1 → item might be in the set
Benefits of Bloom Filters
- Memory efficient (no full keys stored)
- Fast lookups (bitwise operations)
- No false negatives (if it says “not present,” it’s accurate)
Real-World Use Cases
- Signup systems (check if username/email is taken)
- Web crawling (avoid revisiting URLs)
- Databases (Bigtable, HBase skip disk I/O)
- CDNs (check key presence)
False Positives vs False Negatives
| Type | Can Happen? | Explanation |
|---|---|---|
| False Positive | Yes | May say item exists when it doesn’t |
| False Negative | No | Never misses an item that was actually added |
Understanding False Positives in Bloom Filters
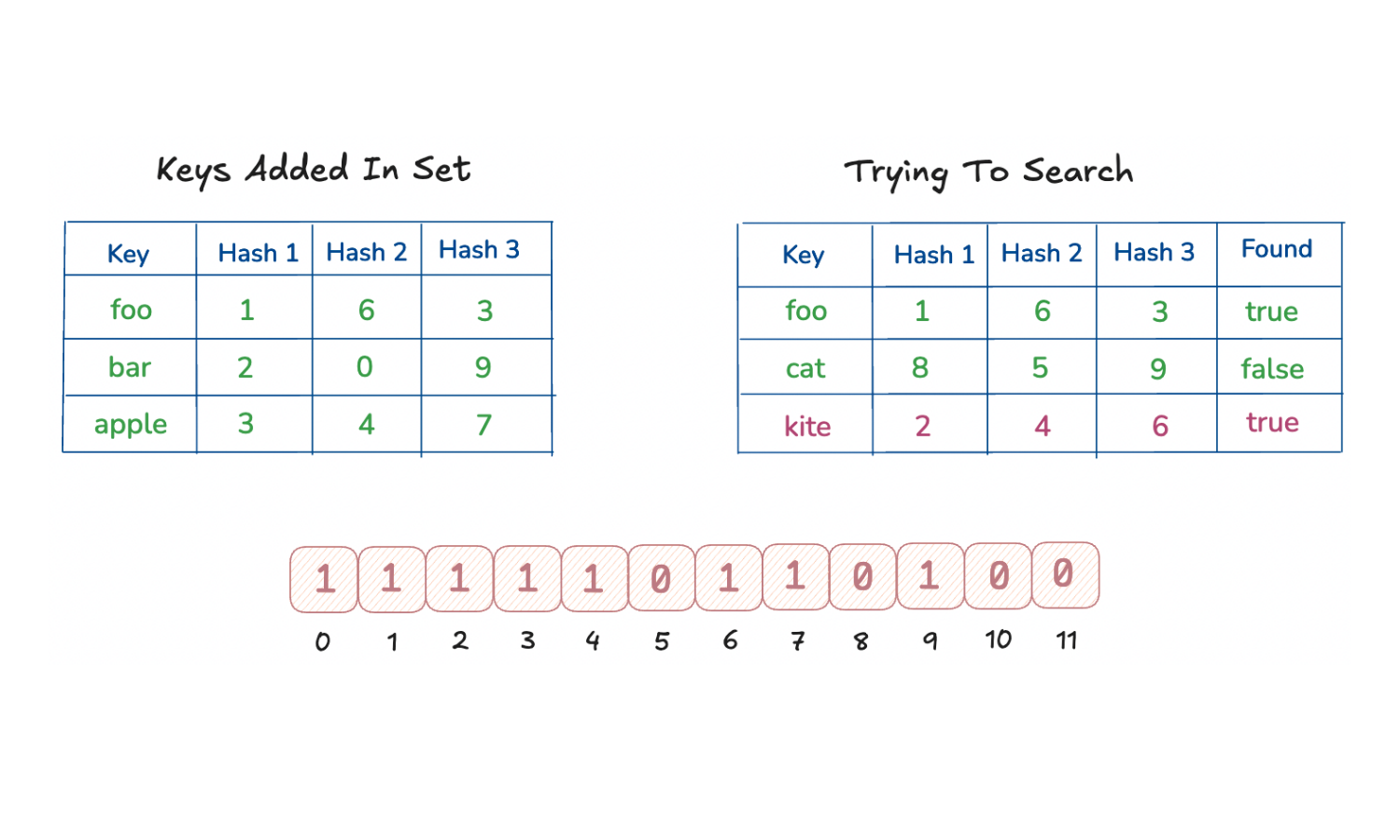
The diagram above demonstrates how Bloom Filters handle lookups and how false positives can occur:
- The keys
foo,bar, andappleare added to the set. - Each key is hashed using three different hash functions, and the corresponding bit positions are set to
1in the bit array. - When we check for the key
cat, one of its hashed positions points to a0, so we know for sure thatcatwas never added — a definite "not present". - However, the key
kitehashes to three positions that are already marked as1by other keys. - Since all its bits are
1, the Bloom Filter returns true, even thoughkitewas never added.
This is a false positive — the filter incorrectly thinks kite exists.
Bloom Filters are designed this way:
they never miss an inserted item, but they may mistakenly say something exists due to overlapping bits.
Limitations of Bloom Filters
| Limitation | Why It Happens |
|---|---|
| No Deletion | Can’t undo which item set the bit; removing breaks integrity |
| No Retrieval | Only stores presence indicators, not data |
| False Positives | Bit collisions grow as more items are added |
Deleting from a Bloom Filter? Use Counting Bloom Filters
How it works:
- Replace bit array with a counter array
- On insert → increment counters
- On delete → decrement counters
Downsides:
- More memory
- Still allows false positives
What Are Ribbon Filters?
Ribbon Filters, developed by Meta, are a more modern alternative to Bloom Filters.
They use structured hashing to improve accuracy and reduce memory further — especially for static data sets.
Advantages of Ribbon Filters
- More compact than Bloom
- Lower false positive rate
- Tailored for static sets like search indexes or key maps
- Efficient with billions of entries
Comparison Table
| Feature | Bloom Filter | Counting Bloom | Ribbon Filter |
|---|---|---|---|
| Memory Efficient | Yes | Medium | Very |
| False Positives Possible | Yes | Yes | Less frequent |
| False Negatives | Never | Never | Never |
| Supports Deletion | No | Yes | No (static only) |
| Stores Items | No | No | No |
| Performance at Scale | Great | Okay | Excellent |
Final Takeaway
When systems need to answer “Have we seen this before?” at massive scale, storing every item isn’t practical. Bloom Filters offer a fast, memory-efficient way to approximate set membership.
They’re not perfect — they can't delete or retrieve — but they’re powerful for “is-it-there?” questions in real-time systems.
Use:
- Bloom Filter → for fast, low-memory lookups
- Counting Bloom → when deletion is necessary
- Ribbon Filter → for compact, static, high-scale filtering
Did You Know?
Bloom filters are used in Google Chrome to check if a website has been visited before, improving browsing speed.